|
Yanjiang Guo Hi! I am a 4th-year CS PhD student at Tsinghua University, advised by Prof. Jianyu Chen. Previously, I received my bachelor's degree in EE also from Tsinghua University in 2022. Currently, I am a visiting researcher at Stanford University and fortunate to work with Prof. Chelsea Finn (Founder of Physical Intelligence). My research focuses on training embodied foundation models that can perform a wide range of tasks in the physical world. I believe that building on top of pretrained foundation models is important for achieving generalization and scalability. To this end, I have explored VLM-based VLA models [5,6,8,10] as well as video-model-based generalist policies [7,9,11]. Prior to these works, I also conducted research on reinforcement learning [1,2,3,4]. Email / Scholar / Twitter / Github
Events:
|

|
Selected Research (* indicates equal contribution)
Generative World Models:
|
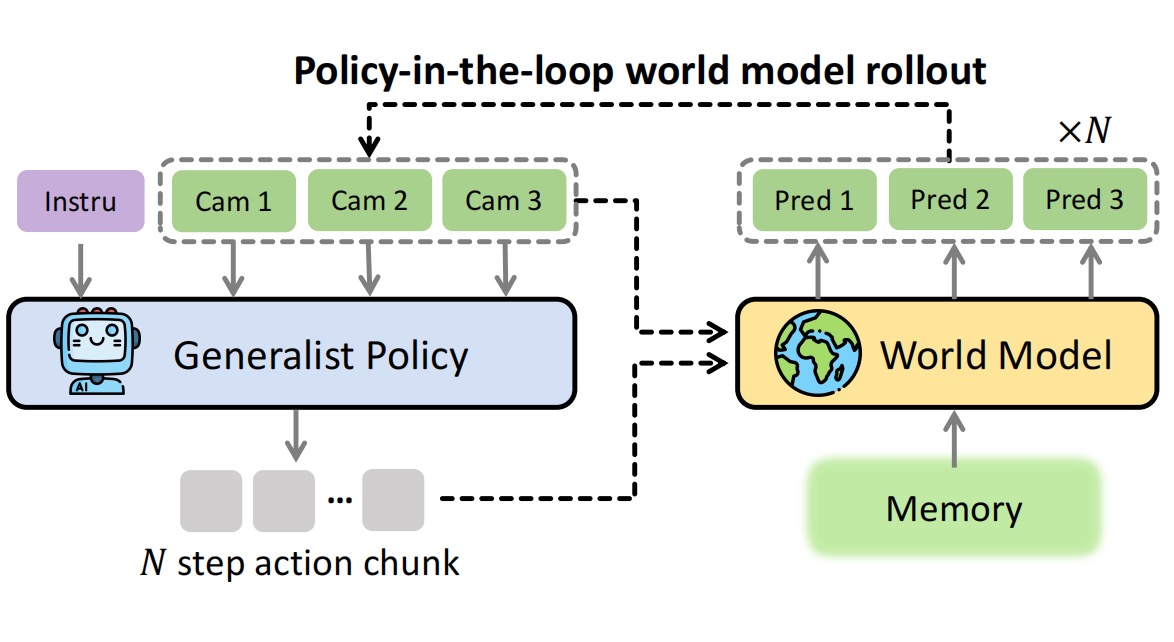
[11] Ctrl-World: A Controllable Generative World Model for Robot Manipulation
Yanjiang Guo*, Lucy Xiaoyang Shi*, Jianyu Chen, Chelsea Finn Arxiv, 2025 project page / code / arxiv / twitter We train a controllable generative world model that can be used to evaluate and improve SOTA generalist robot policy. |

|
[9] Video Prediction Policy: A Generalist Robot Policy with Predictive Visual
Representations
Yucheng Hu*, Yanjiang Guo*, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, Jianyu Chen International Conference on Machine Learning (ICML), 2025 (Spotlight, 2.6%) project page / code / arXiv / twitter / 机器之心 / 量子位 We finetune a general-purpose video diffusion model into manipulation-focused video prediction model to guide policy learning. |
|
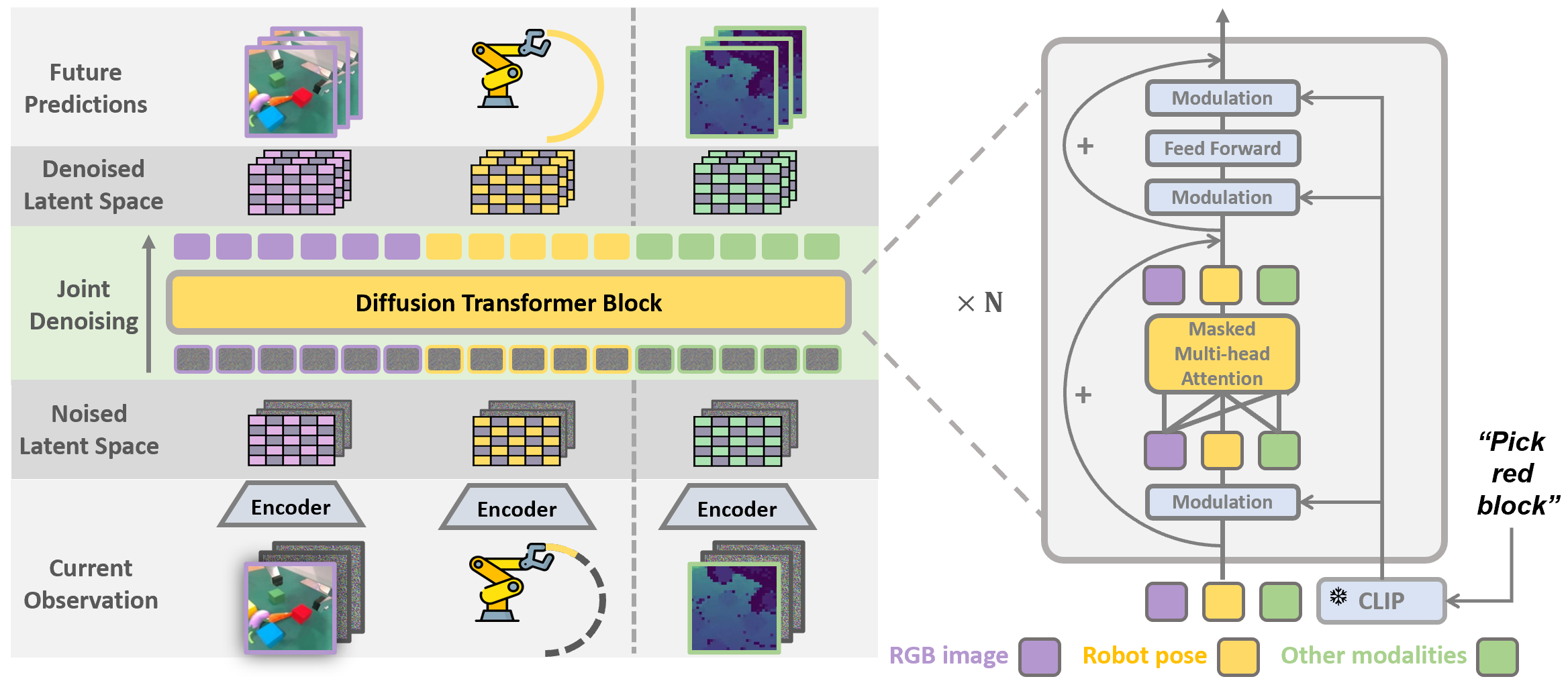
[7] Prediction with Action: Visual Policy Learning via Joint Denoising Process
Yanjiang Guo*, Yucheng Hu*, Jianke Zhang, Yen-Jen Wang, Xiaoyu Chen, Chaochao Lu#, Jianyu Chen# Advances in Neural Information Processing Systems (NeurIPS), 2024 project page / code / arXiv We jointly predict future images and robot actions in a unified DiT network, transfering physical knowledge from internet video data to robots. |
Vison-Language-Action Models:
|
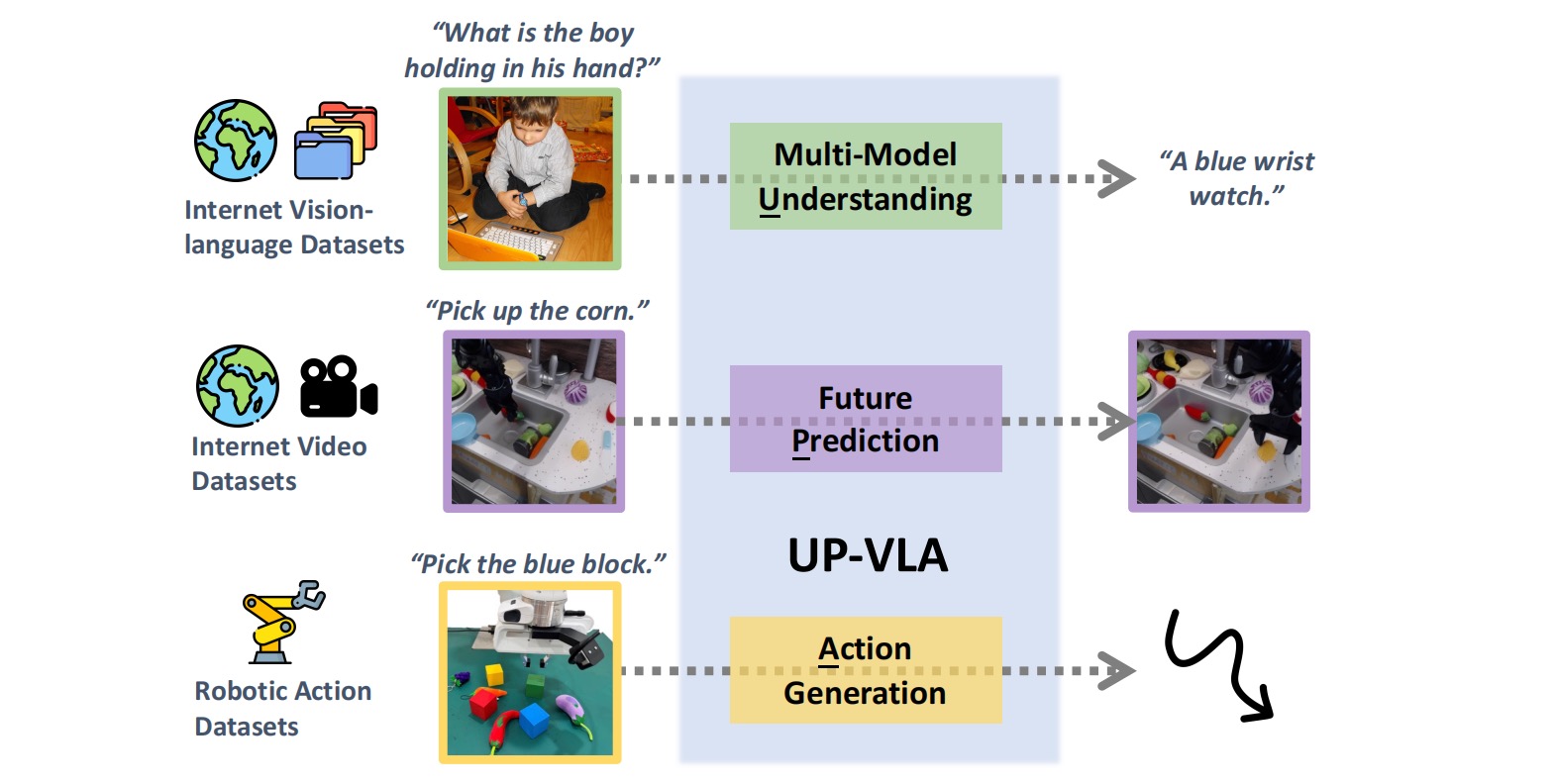
[10] UP-VLA: A Unified Understanding and Prediction Model for Embodied Agent
Jianke Zhang*, Yanjiang Guo*, Yucheng Hu, Xiaoyu Chen, Jianyu Chen International Conference on Machine Learning (ICML), 2025 arXiv / code We incoperate both multi-modal understanding (MMU) and future prediction into VLA model, enhancing both high-level semantic knowledge and low-level visual dynamics. |
|
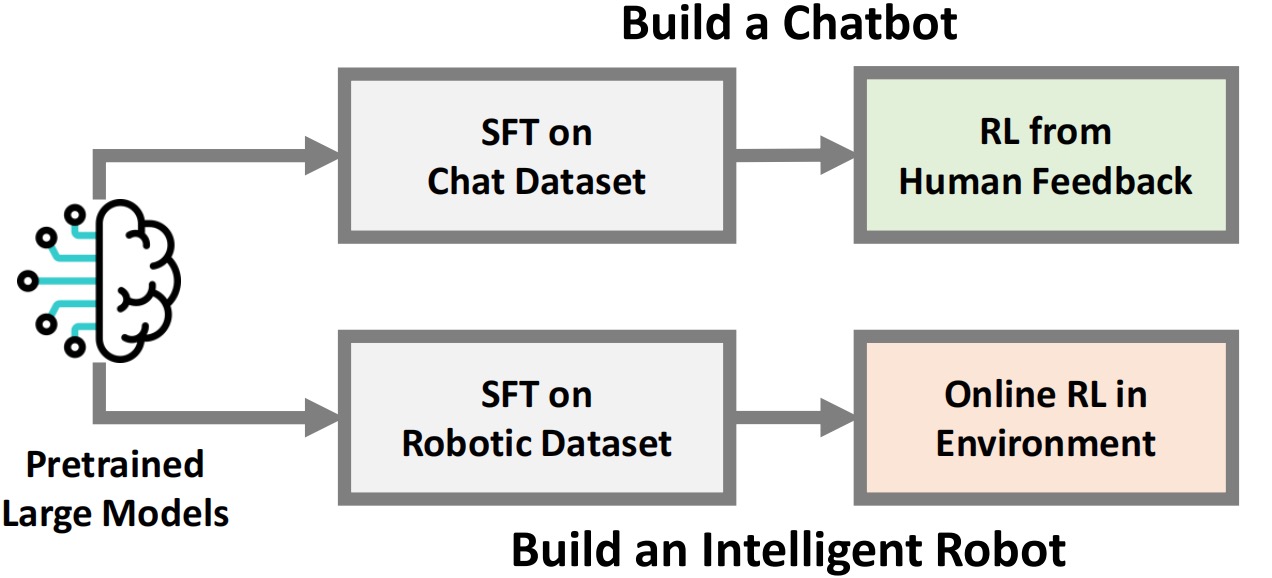
[8] Improving Vision-Language-Action Model with Online Reinforcement Learning
Yanjiang Guo*, Jianke Zhang*, Xiaoyu Chen*, Xiang Ji, Yen-Jen Wang, Yucheng Hu, Jianyu Chen International Conference on Robotics and Automation (ICRA), 2025 arXiv / twitter1 / twitter2 We make some initial exploration on leveraging online RL to improve the VLA model! We notice that online RL for VLA can be extremely unstable and thus we adopted a iterative approach. |
|
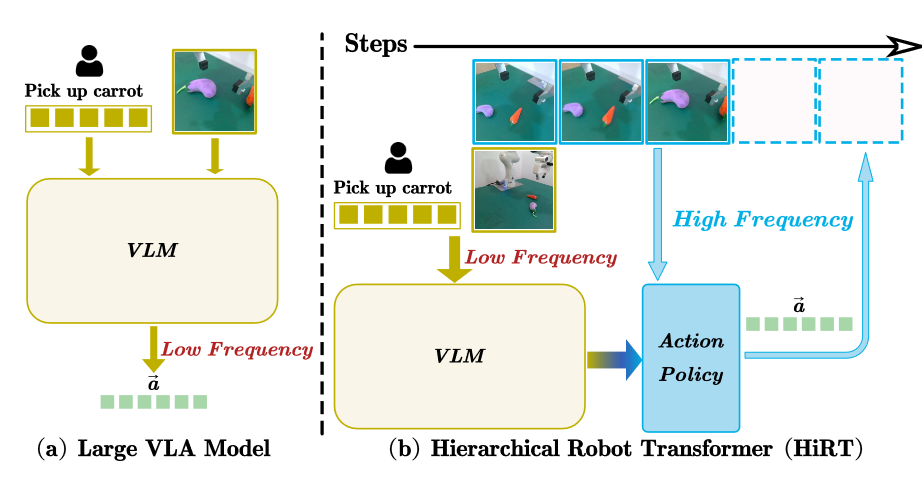
[6] HiRT: Enhancing Robotic Control with Hierarchical Robot Transformers
Jianke Zhang*, Yanjiang Guo*, Xiaoyu Chen, Yen-Jen Wang, Yucheng Hu, Chengming Shi, Jianyu Chen Conference on Robot Learning (CoRL), 2024 arXiv / twitter / 机器之心 We finetune pretrained VLM into VLA models with hierarchical transformers, keeping the generalization ability but also much higher control frequency. |

|
[5] DoReMi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment
Yanjiang Guo* , Yen-Jen Wang*, Lihan Zha*, Jianyu Chen International Conference on Intelligent Robots and Systems (IROS), 2024 project page / arXiv We leverage LLM to pefrom both planning and monitoring, with a fine-tuned VLM as detector. |
Reinforcement Learning:

|
[4] Advancing Humanoid Locomotion: Mastering Challenging Terrains with Denoising World Model Learning
Xinyang Gu*, Yen-Jen Wang*, Xiang Zhu*, Chengming Shi*, Yanjiang Guo, Yichen Liu, Jianyu Chen Robotics: Science and Systems (RSS), 2024 (Best Paper Award Finalists) project page / code / arXiv / 机器之心 We train humanoid robot to master challenging terrains such as stairs, slopes, and snow grounds with zero-shot sim2real transfer. |
Other Publications
[3] Decentralized Motor Skill Learning for Complex Robotic Systems
Zheng Wu, Yichen Xie, Wenzhao Lian, Changhao Wang, Yanjiang Guo, Jianyu Chen, Stefan Schaal, Masayoshi Tomizuka ICRA, 2023 [1] Reinforcement learning with Demonstrations from Mismatched Task under Sparse Reward Yanjiang Guo, Jingyue Gao, Zheng Wu, Chengming Shi, Jianyu Chen CoRL, 2022 |
|
Source code from Jon Barron. |